庖丁解LevelDB之数据存储
作为一个存储引擎,数据存储自然是LevelDB重中之重的需求。我们已经在庖丁解LevelDB之概览中介绍了Leveldb的使用流程,以及数据在Memtable,Immutable,SST文件之间的流动。本文就将详细的介绍LevelDB的数据存储方式,包括数据在不同介质中的存储方式,数据结构及设计思路。
Memtable
Memtable对应Leveldb中的内存数据,LevelDB的写入操作会直接将数据写入到Memtable后返回。读取操作又会首先尝试从Memtable中进行查询。我们对Memtable的需求如下:
- 常驻内存;
- 可能会有频繁的插入和查询操作;
- 不会有删除操作;
- 需要支持禁止写状态下的遍历操作(Immutable的Dump过程)
LevelDB采用跳表SkipList实现,在提供O(logn)的时间复杂度的同时,又非常的易于实现:
SkipList中单条数据存放一条Key-Value数据,定义为:
SkipList Node := InternalKey + ValueString
InternalKey := KeyString + SequenceNum + Type
Type := kDelete or kValue
ValueString := ValueLength + Value
KeyString := UserKeyLength + UserKeyLog
数据写入Memtable之前,会首先顺序写入Log文件,以避免数据丢失。LevelDB实例启动时会从Log文件中恢复Memtable内容。所以我们对Log的需求是:
- HDD磁盘存储
- 大量的Append操作
- 没有删除单条数据的操作
- 遍历读操作
LevelDB首先将每条写入数据序列化为一个Record,单个Log文件中包含多个Record。同时,Log文件又划分为固定大小的Block单位,并保证Block的开始位置一定是一个新的Record。这种安排使得发生数据错误时,最多只需丢弃一个Block大小的内容。显而易见地,不同的Record可能共存于一个Block,同时,一个Record也可能横跨几个Block。
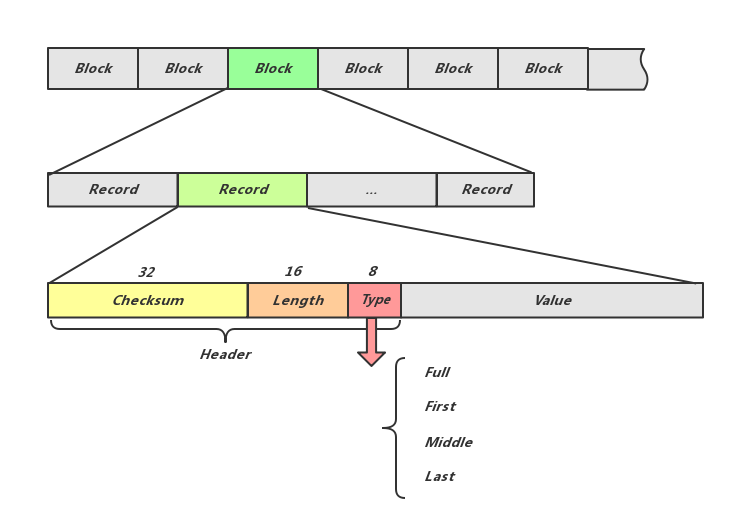
Block := Record * N
Record := Header + Content
Header := Checksum + Length + Type
Type := Full or First or Midder or LastLog文件划分为固定长度的Block,每个Block中包含多个Record;Record的前56位为Record头,包括32位checksum用做校验,16位存储Record实际内容数据的长度,8位的Type可以是Full、First、Middle、Last中的一种,表示该Record是否完整的在当前的Block中,如果不是则通过Type指明其前后的Block中是否有当前Record的前驱后继。
SST文件
SST文件是Leveldb中数据的最终存储角色,划分为不同的Level,Level 0的SST文件由Memtable直接Dump产生。其他层次的SST文件则由其上一层文件在Compaction过程中归并产生。读请求时可能会从SST文件中查找某条数据。我们对SST文件的需求是:
- 支持顺序写操作
- 支持遍历操作
- 支持查找操作
我们将从物理格式和逻辑格式两个方面来介绍SST文件中的数据存储方式。所谓物理格式指的是数据的存储和解析方式;利用确定的物理格式,我们可以存储不同意义的数据,这就是数据的逻辑格式。
物理格式
LevelDB将SST文件定义为Table,每个Table又划分为多个连续的Block,每个Block中又存储多条数据Entry:
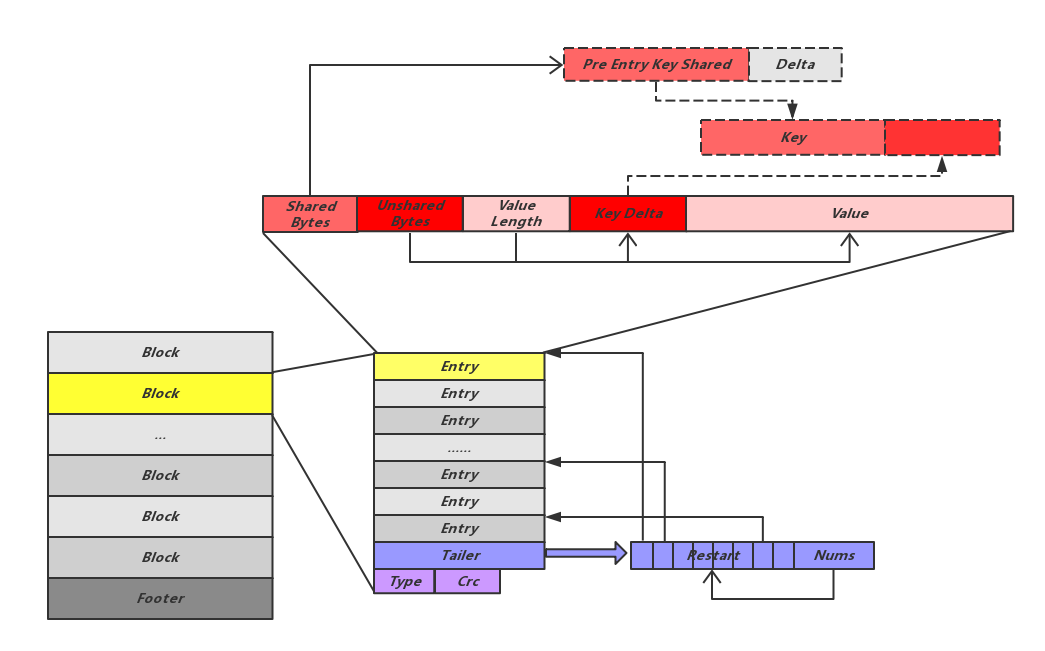
可以看出,单个Block作为一个独立的写入和解析单位,会在其末尾存储一个字节的Type和4个字节的Crc,其中Type记录的是当前Block的数据压缩策略,而Crc则存储Block中数据的校验信息。Block中每条数据Entry是以Key-Value方式存储的,并且是按Key有序存储,Leveldb很巧妙了利用了有序数组相邻Key可能有相同的Prefix的特点来减少存储数据量。如上图所示,每个Entry只记录自己的Key与前一个Entry Key的不同部分,例如要顺序存储Key值“apple”和“applepen”的两条数据,这里第二个Entry中只需要存储“pen”的信息。在Entry开头记录三个长度值,分别是当前Entry和其之前Entry的公共Key Prefix长度、当前Entry Key自有Key部分的长度和Value的长度。通过这些长度信息和其后相邻的特有Key及Value内容,结合前一条Entry的Key内容,我们可以方便的获得当前Entry的完整Key和Value信息。
这种方式非常好的减少了数据存储,但同时也引入一个风险,如果最开头的Entry数据损坏,其后的所有Entry都将无法恢复。为了降低这个风险,leveldb引入了重启点,每隔固定条数Entry会强制加入一个重启点,这个位置的Entry会完整的记录自己的Key,并将其shared值设置为0。同时,Block会将这些重启点的偏移量及个数记录在所有Entry后边的Tailer中。
逻辑格式
Table中不同的Block物理上的存储方式一致,如上文所示。但在逻辑上可能存储不同的内容,包括存储数据的Block,存储索引信息的Block,存储Filter的Block:
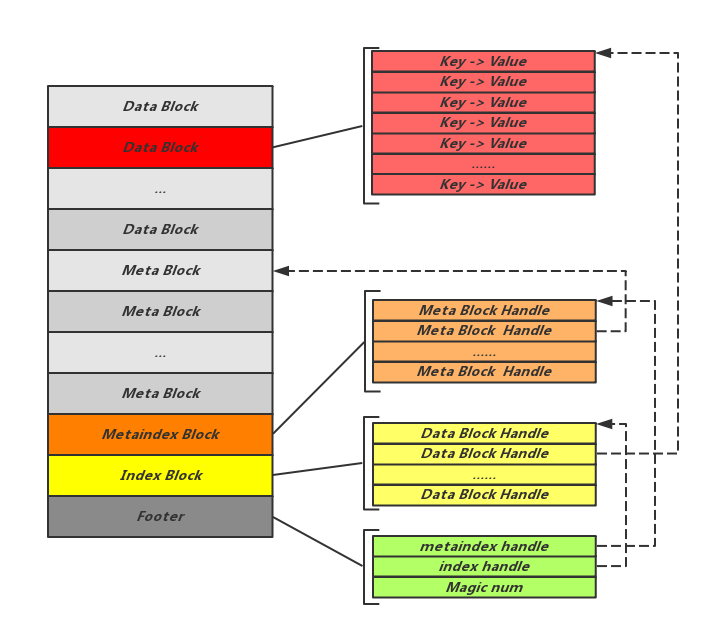
Footer:位于Table尾部,记录指向Metaindex Block的Handle和指向Index Block的Handle。需要说明的是Table中所有的Handle是通过偏移量Offset以及Size一同来表示的,用来指明所指向的Block位置。Footer是SST文件解析开始的地方,通过Footer中记录的这两个关键元信息Block的位置,可以方便的开启之后的解析工作。另外Footer中还记录了用于验证文件是否为合法SST文件的常数值Magicnum。
Index Block:记录Data Block位置信息的Block,其中的每一条Entry指向一个Data Block,其Key值为所指向的Data Block最后一条数据的Key,Value为指向该Data Block位置的Handle。
Metaindex Block:与Index Block类似,由一组Handle组成,不同的是这里的Handle指向的Meta Block。
Data Block:以Key-Value的方式存储实际数据,其中Key定义为:
DataBlock Key := UserKey + SequenceNum + Type
Type := kDelete or kValue对比Memtable中的Key,可以发现Data Block中的Key并没有拼接UserKey的长度在UserKey前,这是由于上面讲到的物理结构中已经有了Key的长度信息。
Meta Block:比较特殊的Block,用来存储元信息,目前LevelDB使用的是仅对布隆过滤器的存储。写入Data Block的数据会同时更新对应Meta Block中的过滤器。读取数据时也会首先经过布隆过滤器过滤。Meta Block的物理结构也与其他Block有所不同:
[filter 0]
[filter 1]
[filter 2]
...
[filter N-1]
[offset of filter 0] : 4 bytes
[offset of filter 1] : 4 bytes
[offset of filter 2] : 4 bytes
...
[offset of filter N-1] : 4 bytes
[offset of beginning of offset array] : 4 bytes
lg(base) : 1 byte其中每个filter值对应一段Key Range,落在某个Key Range的Key需要到对应的filter节中查找自己的过滤信息,base指定这个Range的大小。
总结
本文重点介绍了LevelDB不同介质角色中数据的存储方式,并没有过多的涉及代码细节。因为一旦有了具体的存储格式,相关的代码不过是读写两端的序列化和反序列化。同样,之后几篇博客将要介绍的版本控制,迭代器,缓存等方面的内容也都非常紧密的依赖这些存储格式。
参考
Source Code:https://github.com/google/leveldb
LevelDB Doc: https://raw.githubusercontent.com/google/leveldb/master/doc/table_format.txt
LevelDB Doc: https://raw.githubusercontent.com/google/leveldb/master/doc/log_format.txt
庖丁解LevelDB之概览:https://mgface.com/article/43.html


All comments